Introduction
Increasingly in the modern world, our computers act as extensions of ourselves. Messaging applications augment our means of communication, word processors our methods of expression. The word processor, like the humble pen, acts as a natural continuation of the writer, as does the messaging app to the communicator — themselves becoming as fundamental to the user as the very fingers with which they are operated. This widespread capability to accommodate extension — marrying the mind to external equipment and information — has been instrumental in allowing humans to use tools effectively, but such deep integration comes at a cost.
When tools are entwined with the mind, so too are their constraints, influencing our thinking patterns and habits in subtle yet significant ways. The decisions you make, the way you think, and even what you think are guided in part by the tools you use. Many have mulled over this idea, including Computer Scientist Edsger Dijkstra. “A most important, but also most elusive, aspect of any tool is its influence on the habits of those who train themselves in its use”, he said. “The tools we use have a profound and devious influence on our thinking habits, and, therefore, on our thinking abilities”.
Richard Stallman’s take on this issue, from the perspective of proprietary computer programs, is more dramatic still: “If the users don’t control the program, the program controls the users”. You may be interested, then, in taking control. Learning to manipulate and command the complex machine that is the computer, to craft and refine tools of your own. In doing so, you will develop an understanding of how contemporary computers work, and exercise skills in problem solving, logical thinking, abstraction, and the design of complex systems.
Just a heads up, this series is now discontinued. It took an awful lot of time, but I'm not sure it's any good. Feel free to read the rest of this first part, though. You might also be interested in this series of C screencasts I made. It's paced way too fast, but less rambling than this.
What exactly is a computer, anyway?
At their most general, computers are systems which manipulate “symbols” of sorts, using these manipulations to produce some kind of output or result. A calculator, for example, may compute mathematical results by operating upon some electrical representation of numbers, processing numeric, electrical “symbols” if you will. This is similar to how humans use formal systems of mathematics (e.g. number theory) to find results by manipulating textual symbols like “+”, “-”, and ”42” according to some simple rules. Though these symbols and rules may be inherently meaningless — for example, the minus symbol is literally just a line — under human interpretation, they represent information that is being operating upon to reach some particular goal. If you were to peek inside a calculator and interpret its electrical symbols and rules in the same way its designers did, you could — with some time — understand exactly how it works to compute results.
This “symbol manipulation” definition of a computer curiously allows for humans, and perhaps the universe as a whole, to be considered as computers of sorts. This is no mistake, as the study of computers and computer science essentially boils down to the study of systems and processes in general. But let us take a more narrow definition for the majority of this series of posts, assuming a computer to be an electrical device that manipulates signals using a finite number of voltage ranges.
A computer, under this revised definition, is a digital device. Each of its internal “switches” can be in only one of a finite number of states, and there is no middle ground between these positions. As such — unlike most of the familiar analogue world — small changes can lead to large effects. A single switch out of place can have disastrous consequences. This property, along with the raw speed of these machines, means that your intuitions and analogies from analogue experiences may not apply here. If you want to truly understand digital computing, you need to start afresh.
All computers have some form of “memory”, allowing for the storage and retrieval of symbols, and a number of processing circuits to utilise this memory in symbol manipulation. These circuits for computation are the core of the machine, similar in a sense to the biological “circuits” within the human brain. Depending on their behaviour, groups of these circuits are given different names, such as ‘DSP’ specialised signal processing chips and ‘GPU’ graphics chips. In this series, however, we will be dealing primarily with general purpose central processing units, or CPUs — often simply called ‘processors’. These electrical circuits are designed to follow a set of primitive ‘instructions’, laid out in some form of memory. For example, “add these two numbers”, or “if X equals 10 execute this set of instructions, otherwise execute this other set of instructions”.
An ability to follow a set of assorted instructions allows for general purpose computers, which can be programmed to perform various assorted tasks. These are the types of digital computers we will be discussing in this series, as opposed to special-purpose computers built to solve very specific sets of problems. With this, you can start to get a picture of how current general-purpose digital computers carry out tasks. Execution of a particular job is just the interplay between the CPU and memory, with “real world” input and output carried through connected Input/Output (I/O) devices, such as a keyboard or monitor. As “real world” interactions are usually relatively rare occurances given the timescales involved (CPUs are fast!), the core procedure underlying the execution of a particular task is primarily driven by the calculations of the processor, relying on a memory unit for the storage and retrieval of information.
In reality, computers can have more than one CPU, each with multiple independent “core” processing units inside, allowing them to execute many streams of instructions in parallel, but in this series our discussions will be constrained to only a single core of execution. Additionally, the memory systems in real computers are much more complicated than outlined here. For starters, the memory units in most real computer systems are “volatile” — they cannot retain stored data when the power is turned off. This may seem an odd decision, but with current technology it results in faster memory units, and hence can allow for faster task execution through the speedier storage and retrieval of information. As such, computer systems typically also have some form of slower non-volatile storage such as a hard disk. These allow the computer to “remember” data across power cycles, which is often desirable — for example, to store your music collection, home photos, and saved documents. Persistent storage also makes it easier to issue the computer with commands. Computers today are typically controlled not by re-wiring their internal circuits, but rather by stored programs, each of which consists of a series of instructions commanding the general purpose computer to perform a specific task. Formulating such a series of instructions is called programming. Unfortunately, writing programs accurately and systematically isn’t as easy as you might think, especially for large applications. The art of computer programming requires thinking through many levels of a deep conceptual hierarchy, reasoning about program components at differing granularities and considering their interactions with both the machine and each other.
On the machine level, the instructions that make up an executable program are coded in symbols, like all data that the processor deals with. Each processor “understands” (is designed to act on) a particular programming language of instructions — i.e. particular combinations of symbols — called its instruction set. As different processors may understand different commands, and thus may be fluent in different languages, stored programs should be designed to execute within a particular environment, such as on a processor with a specific instruction set. To execute these programs, roughly speaking, traditional computer architectures expect processors to load instructions from persistent storage into faster primary memory, and then consume instructions one-by-one, in order, performing each in turn. These instructions commonly include arithmetic (“what is X + Y?”), logical (“are both X AND Y non-zero?”), control flow (”if X is non-zero do Y”), memory (load/store), and input/output (“display this to the monitor”) symbol operations.
This process of executing stored programs from memory gives an even clearer picture of how today’s general purpose computers perform tasks. All the applications currently running on the computer displaying this sentence are just complex sets of symbols that command a processor to perform a specific task. This can happen directly, but also indirectly. For example, a program may contain symbols which are read by another program that directs the processor on its behalf — a process called interpretation. There are also programs which cannot be run on any machine, and exist purely to be interpreted — in both senses of the word — by humans. “Program” refers both to sets of commands which do, and do not, consist of “real” machine instructions, but depending on the context it may be used to talk specifically about one or the other. In our discussion of processor program execution, for example, I was referring to the former type.
Let us examine the details of this kind of program execution more closely. An interactive diagram follows to outline the process of execution on an example system with a single CPU and memory unit. A series of instructions has been laid out in memory to continually compute the first power of two greater than 200 (storing this result in memory), and the CPU is set up to execute these. The raw symbols that might make the details of a real system difficult to understand have been replaced with simple English descriptions. Try to fully appreciate how the instructions work together to achieve this goal, and how the interaction between the CPU and memory unit allows this to occur.
Though it isn’t of particular importance to us here, notice that in the above example, like many real processors, the CPU has its own internal memory (e.g. X), in addition to that in the primary memory unit (e.g. MEM[1]), that it allows us to manipulate. The distinction between these is similar to that of short-term and long-term memory in humans. As sending signals to and from a large external memory unit is slow in comparison to sending signals to smaller memories within the processor itself, keeping a small “working set” of data within the CPU can be faster than sending additional requests to the memory unit, continually issuing costly load and store operations for data that is currently being operated upon. The storage capacity of this internal memory is extremely small, however, so the main memory unit is still vitally important for storing larger, longer-term data, and for sharing data between the different components of the machine. In the system presented in the diagram, one example of such “longer-term data” are the instructions that make up the program itself. Our program consists of more instructions than can be stored within the CPU’s internal memory, and so each instruction must be loaded from the memory unit before it can be executed such that the processor knows what it should do next.
These sets of instructions in memory that dictate what tasks the machine should perform, in contrast to the hardware that makes up the physical machine, are considered to be software — information that lives within a system which, compared to the hardware, is intangible and fluid in nature. We have yet to dive into the nuts and bolts of what each instruction actually consists of, but just like everything else in the system, programs are represented as symbols, and these are interpreted by the processing hardware as particular commands. But how does that work? And what exactly are “symbols” in today’s machines anyway?
Symbols & Languages
As we’ve discussed, the circuits inside a computer exchange information electronically. Particularly, through combinations of electrical signals that the machine “understands” and manipulates. These signals are the core of the machine, much like those that fire through neurons in the human brain, and make up the “symbols” that the computer manipulates on the lowest level. Though we won’t discuss the nature of electrical signals within this series, at any particular point in time each of these represents one of exactly two values: “on” or “off”. The electrical details of voltage may get a bit messier than that, but as far as the circuit as a whole is concerned this is a black and white issue — on and off are the only states that matter. Modern computers are digital devices, there is no in-between.
All information within such computers, thus, must be encoded in a series of these “on” and “off” signals. We can equally write these binary states — each of which is called a “binary digit”, or ”bit” for short — as “high” and “low”, “up” and “down”, or “1” and “0”. Combinations of these states can then, under a particular interpretation from the receiving party, be used to exchange information. For example, we can encode numbers in the binary number system, a numbering system making use of only two states. In this system, the binary 0 represents the decimal 0, and the binary 1 represents the decimal 1. Fairly straightforward so far, but now we’ve run out of signals to use, much like at 9 in the decimal system. Thus, we can compose two units in this “ones” column into one unit in a new “twos” column, specifying another signal along with the the first. So the binary 10 (i.e. an “on” signal followed by an “off” signal) represents the decimal 2, and the binary 11 represents the decimal 3. The pattern continues this way, wrapping around to a new, higher-value column when all possible combinations of signals in the previous columns have been used, just like the decimal system. This isn’t particularly important to us right now — it’s just an arbitrary mapping from sequences of binary signals to decimal numbers — but it demonstrates how a mere two states can be more powerful than you might imagine.
We can encode other information in sequences of bits too, like machine instructions. The Intel Core i7 processor I’m using to write this, for example, codes an instruction to halt the machine, bringing instruction execution to a standstill, as the binary sequence 11110100. There’s nothing particularly special about this sequence of on and off signals, but it happens to be what the CPU designers chose, such that the circuitry in my processor recognises it as a command to halt. As alluded to earlier, different processors may use different sequences to represent this command, or may not have a command like this at all. Notice that this same bit sequence, 11110100, can also be interpreted as the number 244 via the numbering scheme discussed earlier. In yet another context, perhaps this sequence represents part of an image file, or a character of text. This concept that all data — and, hence, all combinations of symbols — are, in the absence of interpretation, without inherent meaning is important. The following figure sketches out this idea more concretely, giving a few completely arbitrary interpretations of a four bit binary sequence.
MULTIPLY With knowledge of how a particular CPU codes for its instructions in binary, we can write programs for that CPU by crafting a series of these instructions to be executed in sequence — much like the program to compute the first power of two greater than 200 presented previously, but using a raw symbolic representation rather than English words. Upon attempting to write programs this way that are even moderately large, however, you’ll find the process to be slow, tedious, error-prone, and unnecessarily difficult. It’s a bit like trying to build a physical object atom-by-atom (or quark-by-quark!) — you end up dealing with too many of the unnecessary details. Not to say that thinking on an atomic level is always unwarranted, but that for the most part we should think about things in larger “chunks”. To fix this, we can allow the programmer to write programs in some other form that abstracts away some of the exact details, using a translator program to automate the tedious work of converting this to the relevant sequence of 1s and 0s. These translator programs, like their human counterparts, simply “convert” from one language to another.
The most basic of these more abstract programming languages is called assembly code. This is so close to the raw machine code (i.e. binary instructions) that the two are often confused, just as the words in this sentence can be easily confused with the ideas communicated within it. At core, assembly languages associate each binary machine instruction with a textual representation which the programmer may write instead, as well as a handful of other basic conveniences (such as referring to locations in the code by textual names). An assembly to machine code translator program — called an “assembler” — for the processor in my machine, for example, may allow the programmer to write the instruction 11110100 discussed earlier as the text HLT (and will translate from the latter to the former). HLT is much easier to understand than 11110100, and it is much easier to read, write, and think about programs in assembly code than machine code as a result. A concrete example is the following snippet of x86 assembly code to multiply the numbers 10 and 20 within the internal memory of the processor, where each instruction is displayed besides its binary counterpart.
mov eax, 10 ; 10111000 00001010 00000000 00000000 00000000 mov ebx, 20 ; 10111011 00010100 00000000 00000000 00000000 mul ebx ; 11110111 11100011 hlt ; 11110100
mov eax, 10 ; 10111000 00001010 00000000 00000000 00000000
mov ebx, 20 ; 10111011 00010100 00000000 00000000 00000000
mul ebx ; 11110111 11100011
hlt ; 11110100
As the relationship between assembly code and machine code is fairly direct, assemblers tend to be relatively simple programs. I outlined earlier how the similarity between these languages can result in confusion, but in many circumstances it is perfectly valid to flit between these interpretations, or indeed even more abstract ones. It can be useful to see the sequence 11110100 and think of it as HLT, or to look at the longer sequence 10111000 00001010 00000000 00000000 00000000 10111011 00010100 00000000 00000000 00000000 11110111 11100011 and think of it as “10 × 20”. The execution of a program can always be viewed in larger “chunks” than the instructions understood by the hardware. We can consider, for example, the execution of constructs that are natural to the human programmer rather than those that are natural to the machine, providing a higher level, more abstract overview of task performance. Thinking about things at many different levels of granularity — in different sized “chunks” — is extremely fundamental in computer science, and is a recurring theme of this series.
Though the abstraction of an assembly language provides extreme convenience at a low cost (we don’t lose much control of the machine, as the mapping is very direct), it still has a number of problems. Its key advantage of being such a direct mapping to machine code is also its downfall: assembly code isn’t portable. In writing a program in assembly code for one system, we cannot reasonably expect the same program to work on a different system, as various components, including the processor, may have different instruction sets or behaviours. This is an issue, as many programmers wish for their programs to work on a variety of machines. More fundamentally, though, for most tasks assembly code is still a far too granular way of reasoning about the operations which make up a program. It can be difficult to think about, and thus write, large assembly programs without errors. From many years of attempting this very task, assembly programmers found a number of commonly occurring patterns — sequences of instructions that could be reasoned about as single logical chunks. Using these as core building blocks, slightly more abstract “higher level” languages arose to attempt to resolve some of the issues with assembly languages. One language very much conceived this way is the C programming language, which, as the subject of this series, we will be working with closely.
Other higher level language designers approached this problem from a different angle to C, considering abstractions from a more theoretical perspective. One such family of languages is Lisp. Lisps are extremely abstracted from the details of the machine, and provide a programming model that is very different to that of C, and indeed of current machines. This has important implications on Lisp code, programmers, translators, and program characteristics, but we will not explore these in great detail here.
Regardless of abstraction design decisions, higher level languages solve many of the issues with assembly languages. They can be designed such that they are not specific to any one processor or machine, allowing for multiple translator programs to exist to convert the language to the relevant code for various systems, and they can use abstractions to make writing large, correct programs much easier. This allows the programmer to think less about the minutiae of the machine and more about the logic of the program itself — breaking down any given program task into a number of logical language operations, rather than a vast array of smaller machine operations.
Unfortunately, these rather important benefits don’t come for free. By communicating with the machine through a more complicated translation process, we lose some amount of control. Though most languages give strict guarantees about what the generated code will do, we usually don’t know the exact machine instructions that will be used to do it. We have to trust the translator to do a good job. This issue is more pronounced in some languages than others. Languages that are very much related to the underlying details of the machine, like C, tend to have simpler mappings — giving a much better idea of what machine code may be generated from any given snippet of C code. Lisps, on the other hand, have a far less direct translation to contemporary instruction sets, and hence can make it more difficult to reason about certain properties of generated programs. This is particularly important when considering the performance of programs, which relies ultimately on the instructions that the machine actually has to execute. Curiously, though, there is a performance benefit of sorts from using more abstract “higher level” languages in that the translator — having more information about the intention and meaning of our code — may perform optimisations on our behalf. These machine optimisers actually tend to be better at some optimisation tasks than their human counterparts, their effectiveness depending not only on their internal logic, but also on the design of language they are translating from, and the machine architecture they are translating to. Machine optimisers are by no means better than humans at all optimisation tasks, however. For those that seek optimal performance on current machines, the path towards this lies within cooperation between human programmers and machine analysis tools.
Optimal performance is not usually the end goal, though. Even if it were attainable, most projects strive for “good enough” performance characteristics for their use cases. Execution speed is a factor which must be weighed against a number of others, including program correctness, maintainability, readability, flexibility, and development time. There are a number of properties that programmers look for in programming languages, and these must be compared and contrasted against the needs of a specific project. Different programming languages are best suited to different tasks, and it is not usually the case that one language is simply “better” than another. It is rather that for a specific project, the programmer should select the right tool for the job — taking into account their own preferences and experiences in combination with the properties of the language itself. Given that this is a series of posts on the C language, then, in what situations would C be a good choice of language? And what really is the C programming language anyway?
C
C is a general-purpose programming language in which the programmer specifies a number of abstract commands that broadly specify how a machine should go about completing a task. We’ll see the details of some of these commands — called statements — shortly, but for now each can be considered, as alluded to earlier, as mapping fairly directly to a handful of general-purpose machine instructions. C was originally developed in the early 70s at Bell Labs, and has since become one of the most widely used programming languages in the world.
An enormous amount of software is written in C and C++, the latter of which is essentially a variation on C that changes some core behaviour and adds many new features. For starters, the most popular operating systems (Linux, macOS, Windows, iOS, Android, BSDs), web browsers (Chrome, Firefox, Safari, Edge), and huge swaths of desktop software (Microsoft Office, Adobe Photoshop) and embedded systems software (in cars, spacecrafts, games consoles).
From this, it should be clear that C is an extremely useful (and popular!) language. It provides a lightweight wrapper over raw machine code that gives enough abstraction from the details for significantly enhanced portability and productivity over assembly programming, while retaining much of the raw control over the machine. This makes C extremely powerful, and especially useful for high performance programming. You can write any program you want in C, but its core advantage over many other higher level languages is really in the speeds that programs translated from well-written C can reach. For this reason, the vast majority of AAA computer games — which are often required to consistently perform complex calculations and render compute-intensive images every fraction of a second — are primarily written in C or C++, often with sprinklings of assembly code for when the going gets tough.
But the C language is of more general importance than just its practical applications. If you want to write software of any kind, learning C can be an extremely useful experience. The language is so close to contemporary machine code that it is often considered a low level language with a high level syntax (i.e. a wrapper around assembly code!), yet it’s portable, and significantly easier than assembly to write programs in. Even if you never write any important software in C, learning the language gives you a better understanding of what goes on “under the hood”, and provides insights into many of the decisions underlying today’s computer systems. C bridges the gap between the physical reality of hardware and the abstract world of software, and failing to appreciate this layer can leave higher level programmers blind to what is really going on under their feet. That being said, learning C as a first language is a somewhat polarising idea within the wider programming community. Though I am of the opinion that doing so can be greatly beneficial, many claim that that the language is too complicated and difficult for this purpose. Certainly there are simpler and more elegant languages to learn, but I do not think that difficulty is necessarily a good counterargument. If anything, difficulty can be a good thing provided it can be overcome — in getting stuck and working through problems, you can learn an awful lot.
The unrestricted control that C gives the programmer over the machine can also be a point of contention. With great power comes great responsibility, and although the tools that C provides can be put to great use by good C programmers, they also make it extremely easy to inadvertently create bad programs with security flaws, incorrect behaviour, crashes, etc. I see this as more of an argument around the usage of C than against the language itself, though. The whole point of C is to expose the machine in its entirety so that it can be put to good use by careful, skilled programmers. If you don’t want that, or don’t find that to be suitable for a particular project, then you should probably use a different language. Let’s not forget that the majority of what C exposes in its behaviour is simply the reality of the machine itself. C shows the programmer the truth, offering an opportunity to look behind the curtain of abstraction and interact with the machine directly. This is messy, and this is dangerous, but it can also be extremely powerful.
Having discussed many of the ideals and motivations behind C, it’s probably about time we actually see some. A snippet of C code to list the prime numbers up to 593 follows.
#include <stdio.h>
#define N 593
void main(){int a[N],i,j;for(i=2;i<=N;i++)
a[i]=1;for(i=2;i<=N;i++)if(a[i])for(j=i;i*
j<=N;j++)a[i*j]=0;j=0;for(i=2;i<=N;i++)if(
a[i]==1)printf("%d%c",i,++j&1?'\t':'\n');}#include <stdio.h>
#define N 593
void main(){int a[N],i,j;for(i=2;i<=N;i++)
a[i]=1;for(i=2;i<=N;i++)if(a[i])for(j=i;i*
j<=N;j++)a[i*j]=0;j=0;for(i=2;i<=N;i++)if(
a[i]==1)printf("%d%c",i,++j&1?'\t':'\n');}
Look scary? It’s supposed to. Most C code doesn’t actually look like this, and no sane programmer would write this, but sticking with the theme of “the programmer is smart, let them do what they want”, C is a language that lets you write extremely unreadable code if you wish to. You might notice that there’s a little  icon to the left of the code snippet. This is the run button. You can actually translate and execute the above snippet right in your web browser by hitting this — go ahead, try it! For now, even though I don’t expect you to understand anything in the code, I encourage you to try to find the place where the maximum value of 593 is set. In fact, this seems a good place to introduce the “challenges” within the series.
icon to the left of the code snippet. This is the run button. You can actually translate and execute the above snippet right in your web browser by hitting this — go ahead, try it! For now, even though I don’t expect you to understand anything in the code, I encourage you to try to find the place where the maximum value of 593 is set. In fact, this seems a good place to introduce the “challenges” within the series.
Throughout the various chapters that make up this series, you will see a number of challenges presented in specially highlighted boxes like the one below. These problems are designed to test some aspect of your knowledge that has been built up within the chapter. In this case, if you are able to modify the code snippet below such that it prints the primes up to 151 (in the same format as before), you can consider this challenge block to be completed.
Modify the following code snippet to print the primes up to 151, using the same format as is used by default.
#include <stdio.h>
#define N 593
void main(){int a[N],i,j;for(i=2;i<=N;i++)
a[i]=1;for(i=2;i<=N;i++)if(a[i])for(j=i;i*
j<=N;j++)a[i*j]=0;j=0;for(i=2;i<=N;i++)if(
a[i]==1)printf("%d%c",i,++j&1?'\t':'\n');}#include <stdio.h>
#define N 593
void main(){int a[N],i,j;for(i=2;i<=N;i++)
a[i]=1;for(i=2;i<=N;i++)if(a[i])for(j=i;i*
j<=N;j++)a[i*j]=0;j=0;for(i=2;i<=N;i++)if(
a[i]==1)printf("%d%c",i,++j&1?'\t':'\n');}
C99
Though we’ve talked about C as a single language thus far, the reality is that there are a number of versions of the C language. Each of these variants — at least, the ones we care about — are defined within a standards document that dictates how the language should look and behave. Translator programs are written to attempt to follow this standard such that the language is consistent to the degree specified by the standard across different translators (typically implemented by different people). Unfortunately, the standard is fairly complex (and in places, ambiguous!), so many practical implementations of it (i.e. real translator programs) differ subtly from the desired behaviour. In fact, it may be the case that no C translators are truly standards compliant! In practice, though, popular implementations are usually good enough that we should not run into issues.
In this series, we will be following the ISO 9899:1999 C standard, informally known as “C99”. For whatever reason, the official standard isn’t freely available, but a post-C99 committee draft document “WG14 N1256” is. This is essentially identical to the officially published standard, with the addition of a few corrections and amendments. If you want to learn C but don’t want to read anything else that I have to say, go and read this! Although it’s not the most thrilling read, it has all the details of C99, and is the source to consult if you aren’t sure how the language is supposed to behave.
Since 1999, newer versions of the C language have been released. C11, for instance, was (somewhat predictably) released in 2011. So why use C99? For starters, newer versions of the language haven’t significantly departed from the way things were in C99. Most of the fundamentals are exactly the same, and so much of the time it doesn’t really matter what core version of the language you’re learning. The C code we saw earlier to print primes, for example, should work just fine when translated by both C99 and C11 translators. There may be additional features in newer language versions that you should be aware of (such as the alignment control or multi-threading features in C11), but these can be learned separately from the core language. In contrast, versions of C before C99 differ in more significant ways. Language features that have become extremely fundamental are lacking in older versions (for example, in C89). C99 also acts as a basis for the core functionality available in C++, while later versions of C begin to create a deeper divide between the two languages. Lastly, C99 is a mature and well supported version of the C language. There are an abundance of translators and huge number of written resources around C99, and these are invaluable to the process of learning C.
The Series
This series of posts aims to help build the reader’s intuition and understanding around a number of core topics, including the C language, computer programming in general, and many broader ideas within computer science. By the end of the series, capable readers should be able to read and write C code at an intermediate level, and contemplate larger ideas in computer science and software design. Beware, though, this kind of insight does not come effortlessly. In working your way through the series, it is likely you will hit a number of challenges and difficulties. Especially at the points where your current intuitions and worldviews don’t match those of the conceptual systems within which the ideas we will discuss lie. This is a good thing, it means you’re learning. I have faith that, with time, determined readers can overcome such challenges and emerge with insight and intellect.
In its complete state, the series is structured into just over twenty parts. As there is much to discuss in each, it would be ill-advised to read them all in quick succession. The chapters make use of the interactive medium of the Web, and you are advised to fully engage with the material both intellectually and literally, ensuring a good understanding of the contents of one chapter before moving to the next. Though I will occasionally explore interesting tangents, there is much to discuss, so we will not spend much time revisiting material. Also, keep in mind that there is no need to rush. Everything will still be here whenever you’re ready to come back. Even if you aren’t actively thinking about the series in the mean time, it might be worth letting your mind mull over some of the broad ideas. And let’s not forget the most important part: spend time programming! Practice makes… well, not perfect per say, but certainly it makes for great improvement. Trying to go through this series without doing any programming would be a fruitless endeavour. In following each chapter, I suggest working through any challenge tasks presented, in addition to independently writing programs to satisfy your own curiosities. Programming is the only way to get properly acquainted with the big ideas presented in this series.
How, then, can you set up an environment to read and write programs in C on your very own computer? Fundamentally, there are three important parts you will need: some way of writing the textual C code, some way of translating this text into something you can run, and some way of running this result. C is usually translated directly into executable machine instructions, and so we will assume that running a program is the easy part. You can simply pass the instructions that come out of the translator to a processor within your computer designed to execute instructions of this format. Next up, we need a way of writing text. Typically this is accomplished via a program called a “text editor”, which allows you to enter raw text data and save this to some form of storage, such that it can, for example, be viewed by other programs. This may seem similar to the concept of a word processor, however these ideas are distinct. Word processing programs such as Microsoft Word will not suffice for this task as they store the textual data in a more complicated format than the translator expects, including not only the text, but additional information about how it is formatted (font, colour, emphasis, etc.). Instead, we must write our C code in an extremely simple format known as “plaintext”. This simply stores the data for each textual character in order, and is the standard format that both C translators and text editor programs use.
Text editor programs are widely available, and are usually fairly easy to install — so go ahead and set one up! I suggest one of Sublime Text, Notepad++, Atom, vim, or emacs. Once you’ve downloaded, set up, and opened a text editor program on your machine, you should be presented with a clean slate for writing new text documents — something like the following:
This allows you to write text, and save it in the plaintext format as a file with a particular name in some location. Often, files are named such that the last few characters give an indication about what the file contains. This doesn’t alter the data stored within the file itself, but just provides a hint as to what data might lie within. C language text files are usually given the .c file extension. This means that rather than saving some C code from your text editor as a file with name test.txt or just test, it’s probably a good idea to name it test.c, even though many programs will only care about the text data within the file itself.
Ability to run programs: check. Text editor: check. Now we just need to wire these together such that the output of your text editor (such as a .c file) can become the input to your machine (i.e. machine instructions, coded in binary). We need a translator program. More specifically, we need a particular type of translator that given text in one computer language (e.g. C99), outputs the translation of the entire input into another computer language (e.g. machine code). These class of translator programs are called compilers, are the typical choice for translating C code. Unfortunately, C compilers can be a little more difficult to set up than text editors, and much of the details depend on which operating system you’re using. As such, I will not go through all the nitty gritty details for setting up a compilation environment in every possible machine environment here. Instead, I will simply offer a broad outline of steps that can be carried out on each platform, linking to external resources where they may be helpful:
- Users of macOS: simply open “Terminal.app” (for example, via Spotlight), and enter the command
xcode-select --install. After following the resulting set of installation steps, you can compile code usingclangvia the terminal, as will be described shortly. - Users of Linux: the steps depend on the particulars of your distribution and environment. Most distributions come with the
gcccompiler, which you can use as will be described shortly. Ifgccis not present on your machine, you are advised to install it (orclang) from a package manager, or from source. - Users of Windows: rather than use an integrated text editor and compiler like most Windows users, I recommend compiling via the command line. To do this, you can install Visual Studio 2015 Community Edition, then open “Command Prompt”, and run vsvarsall.bat (or, better yet, set it to run automatically). Having done this, you can compile code using
clvia the command prompt, as will be described shortly.
If you’re having trouble following these steps, there should be plenty of resources to help you out online. The ability to search for information effectively is a critical skill for programmers (and most everyone in the modern world) to have, so it’s good practise.
After setting up your environment in accordance with these recommendations, you should have the tools to run a translator program — clang, gcc, or cl — through a terminal program in order to compile C programs on, and for, your machine. The wad of indirection between the programmer and the machine in this process is a common cause of confusion. The programmer typically interacts with a terminal program, which in turn interacts with a shell, which interacts with the operating system, which interacts with the machine. That’s far from a straightforward way to communicate. Unfortunately, we don’t have time to go into each of these components in detail (doing so would produce another whole series worth of material), however I will quickly sketch out how these parts interact before we move forwards and finally compile and run some C code. Don’t worry if you can’t completely follow all the upcoming details about operating systems, shells, and terminals — I just want to provide a rough sketch of how these things interact before we start making use of them.
Operating Systems & Shells
Despite our discussions around the theory of program execution so far, most programs do not run with full control over a machine. Instead, the typical user runs an operating system (OS) — a set of chosen, ‘privileged’ programs, usually run with full control over the machine, to manage the computer’s resources. Particularly, operating systems control the running of other, less privileged, “normal” programs (mere peasants), and provide common services for these. A common point of confusion here is that what programmers typically refer to as an operating system differs slightly to what consumers usually mean by this term. While consumers may think of the user interface and pre-installed programs as a part of the OS, computer scientists typically consider only the privileged ruling core of the operating system known as the “kernel”.
Modern operating systems place great emphasis on this separation between privileged and unprivileged programs, attempting to keep the two entirely separate. This is typically achieved not by forbidding less privileged “normal” programs direct access to the processor (vetting all instructions before execution, requiring approval from the ruler), but by putting the processor into a less powerful state before handing over control to them, such that attempts to execute certain instructions will result in the operating system being called upon to handle these permission violations (“’Ello ’ello, what’s going on ’ere, then?”). This mechanism is also how unprivileged programs running on contemporary processors typically communicate with the OS kernel — there are certain instructions called “system calls” that are designed for use in unprivileged programs such that the OS can service requests to perform privileged operations like reading data from I/O devices.
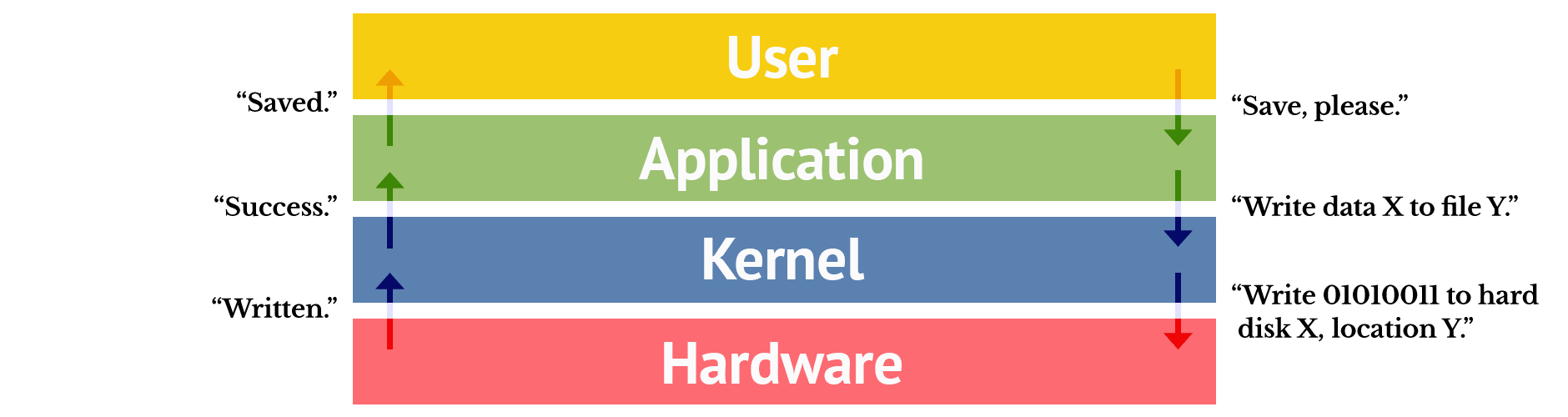
One such “common service” provided by many operating systems is the filesystem. This gives programs a unified way to store and retrieve auxiliary data. Take the text editor program you installed, for example. Whenever you read or write a file within this, the program you are interacting with (e.g. vim) communicates with the kernel (e.g. the Linux kernel), which then executes privileged instructions to read and write data to and from a storage medium as appropriate to fulfil your request. A compiler program operates in a similar way, reading source files (e.g. text files of C code) and writing output files (e.g. of executable machine code).
Not all programs run under operating systems though. Particularly, fixed-function applications that are relatively unexposed to the external world often have no need for an OS. The software within a fridge, for example, may have no need for the separation or common services of an operating system — it can run more efficiently in privileged mode. As such, when we discuss programs in this series, keep in mind that we may be talking about privileged “bare metal” code (such as kernel code), or unprivileged code running at the mercy of other software (such as that of the web browser viewing this page). There are deeper levels too, such as “super-unprivileged” programs that are managed by programs without full execution privileges themselves! We will not explore the details of such systems in this series of posts, however.
Let us return to thinking about programs that run under operating systems — as is almost certainly the case with your development environment. It’s all well and good to have executable programs to edit text and compile C stored on disk somewhere, but how can the user actually go about launching these programs? The answer is simple, the user can interact with an interface program which performs actions and communicates with the kernel on his or her behalf. The graphical interfaces of consumer operating systems are a perfect example of this — the user can use the mouse to select certain actions, and the interface program performs and displays the results of these. Historically, however, users instead interacted with the machine by means of a command-line interface. This involves issuing commands by entering lines of text, typically yielding an interface that looks something like the following:

This alternative method for interacting with the kernel can be hugely more efficient than graphical interfaces for power users that are familiar with the commands, and hence is often favoured by programmers. Such an interface is also commonly preferred by beginner programmers, as it’s easier to write programs for, bypassing the need for all sorts of additional cruft in the code. A program that implements a textual command interface like this called a “shell”. Common examples include bash, which is an extremely common default on *nix machines such as macOS and Linux, and zsh which gaining popularity in this same space.
Rather than choose between textual and graphical interfaces, however, often it would be convenient to have a compromise in which a command line interface is accessible from within a graphical one. This is achieved via a “terminal emulator” or “command prompt” program, which acts as a wrapper program in the graphical interface to run a shell — a textual interface. There’s a whole lot of history behind terminals and shells, but we won’t go into that here. All you need to know is that macOS’ “Terminal.app”, and the various Linux terminal applications should serve this purpose for you. Similarly, Windows has the “Command Prompt” — this is somewhat of an outlier, however, as it functions as both a terminal and a shell. Thus, while you can use the same terminal application for multiple shells in macOS and Linux, to change shells on Windows you must use an entirely different terminal application (such as Windows PowerShell).
Since we will be using it regularly, you must have a basic understanding of the terminal and shell applications within your desktop environment. Users of the vim and emacs text editors should feel relatively at home with this, but those used to a graphical environment may find it a little jarring at first. Most shells keep a current directory which they are operating in called the “current working directory” — you should know how to change this (e.g. through the cd command), and how to perform basic filesystem operations such as viewing, moving, and copying files (e.g. mv and cp in bash). macOS and Linux users using the bash shell, which is frequently the default, can get a gentle introduction to this here, while Windows Command Prompt users may wish to get acquainted with the commands here.
In addition, you will need to know how to invoke a C compiler from your shell. As your compiler and text editor are themselves just programs, these can typically be launched — like other properly installed programs — from a command line shell interface by simply typing the name of the program’s executable file (e.g. clang, gcc, or cl) followed by any additional information you want to pass to the program. Using the recommended compilers within the three major operating systems, you can use one of the following commands within the default shell:
- macOS: in “Terminal.app” you can run
clang test.c -o testto compile the C source filetest.cin the current working directory, generating the executabletest. This executable file can then be run with./test. - Linux: in most “normal” shells (including
bash), the commands are identical to those used in macOS, but withgccin place ofclang. - Windows: using “Command Prompt” you can run
cl test.cto compile the C source filetest.cin the current working directory, generating the executabletest. This executable file can then be run with the commandtest.
In order to test this environment, let’s compile and run a simple C program. What follows is the C99 source code of a simple program to convert input distances in yards to metres. There’s no need to attempt to understand this quite yet — for now, it’s just a bunch of symbols that happen to form valid C99 source code in order to test your development environment.
#include <stdio.h>
int main(void)
{
int yards;
printf("Enter a number of yards: ");
scanf("%d", &yards);
printf("%d yards is %f metres\n", yards, yards * 0.9144);
return 0;
}#include <stdio.h>
int main(void)
{
int yards;
printf("Enter a number of yards: ");
scanf("%d", &yards);
printf("%d yards is %f metres\n", yards, yards * 0.9144);
return 0;
}
If you save this text as a file named test.c, compile it into an executable (e.g. with clang test.c -o test), and then run this (e.g. by running ./test), you should find that the program compiles and runs as expected. Congratulations, you just compiled and executed your very first C program! It might not look like much — performing simple text-based processing within a terminal window — but as we will see near the end of the series (should I ever finish writing it), this form of program is not as far away as it might seem from its slightly more complicated graphical counterpart.

Syntax and Semantics
Sometimes, when you’re deep into reading the more complicated chapters that make up this series, it can be a real pain to exit that environment to experiment with some code. As a result, many readers of traditional code resources just won’t do so, sufficing to read the examples given instead of writing and executing their own programs. This is a great shame, as programming is a skill acquired by practise, and much is gained from prodding and probing the language first hand.
To help alleviate this issue, as outlined earlier, most code blocks within this series of posts can be modified and executed right from the comfort of your own web browser. By pressing the icon to the right of a code snippet, the program will run in a terminal of sorts within your web browser.
#include <stdio.h>
int main(void)
{
int yards;
printf("Enter a number of yards: ");
scanf("%d", &yards);
printf("%d yards is %f metres\n", yards, yards * 0.9144);
return 0;
}#include <stdio.h>
int main(void)
{
int yards;
printf("Enter a number of yards: ");
scanf("%d", &yards);
printf("%d yards is %f metres\n", yards, yards * 0.9144);
return 0;
}
Though this doesn’t perfectly emulate a real C99 translator (it isn’t standards compliant), this can be useful for getting a feel for the language by experimenting with new ideas or making small modifications to example programs. To emphasise, this is not a replacement for a real C compiler. It accepts some programs that aren’t valid C99, fails to process others that are, and in some cases simply behaves differently than a valid C99 translator would. If in doubt, check the C99 specification and use a mature compiler like gcc or clang. If you try something a bit obscure or weird with the online translator, there’s a good chance that it will do the wrong thing.
On this topic, let’s see how translator programs deal with invalid inputs. The following is an example of some text which is not valid in C99.
Dear Compiler,
Please could you generate an executable that does the following on this machine when executed:
1. Print the text "Enter a number of yards"
2. Take a whole number input from the user
3. Convert this input from yards into metres
4. Display this converted value in metres to the screen
Thanks,
ProgrammerDear Compiler,
Please could you generate an executable that does the following on this machine when executed:
1. Print the text "Enter a number of yards"
2. Take a whole number input from the user
3. Convert this input from yards into metres
4. Display this converted value in metres to the screen
Thanks,
Programmer
Upon trying to translate and execute this program either locally or using the online translator, you should find that things don’t exactly go as planned. The translator emits one or more errors (and possibly a number of accompanying warnings), to indicate that it cannot compile this source code. Particularly, clang gives me the following:
test.c:1:1: error: unknown type name 'Dear'
Dear Compiler,
^
test.c:1:14: error: expected ';' at end of declaration
Dear Compiler,
^
;
test.c:3:1: error: unknown type name 'Please'
Please could you generate an executable that does the following on this machine when executed:
^
test.c:3:13: error: expected ';' after top level declarator
Please could you generate an executable that does the following on this machine when executed:
^
;
4 errors generated.test.c:1:1: error: unknown type name 'Dear'
Dear Compiler,
^
test.c:1:14: error: expected ';' at end of declaration
Dear Compiler,
^
;
test.c:3:1: error: unknown type name 'Please'
Please could you generate an executable that does the following on this machine when executed:
^
test.c:3:13: error: expected ';' after top level declarator
Please could you generate an executable that does the following on this machine when executed:
^
;
4 errors generated.
Cryptic! Most translators will do a poor job at giving human-readable errors for this source as the “C” code we gave it as input wasn’t even close to being correct. The syntax of our program code was very much wrong — that is to say, the arrangement of characters was not at all valid within the C99 language. The syntax of a program is contrasted with its semantics, its meaning. While translators should always catch errors in the program’s syntax, they are far less likely to catch issues with incorrect semantics — i.e. programs which are technically correct C99 code, but don’t do what you wanted them to.
The concepts of syntax and semantics exist in natural languages too, though from slightly different perspectives. Particularly, when linguists discuss the “semantics” of natural languages, they typically understand semantic errors to occur within sentences which are grammatically correct but have no meaning such as “Colorless green ideas sleep furiously”. Meanwhile, programmers tend to focus on semantic errors involving a mis-match between what was intended and what was represented — for example, a program which was meant to convert metres to yards, but, due to a mistake, performs the conversion incorrectly. These kind of semantic errors also exist in natural languages, and in common conversation are typically followed by a sentence like “Wait, that’s not what I meant!”. As programmers deal with much more complex “sentences” in programming languages than are typically dealt with in natural languages, these mistakes can be subtle and are extremely common.
Syntax errors carry over more straightforwardly, although programming languages typically have a more strictly defined syntax than natural languages. The sentences “Gb or, be abg gb or, gung vf gur dhrfgvba” and “Furiously sleep ideas green colorless” are both examples of syntactically incorrect English. These sentences do not make sense as they are simply not valid in the language. You should be able to see why these errors are significantly easier to catch than semantic errors — who’s to say whether the meaning of a sentence is “right”, or whether the writer did or did not intend to do something? Regardless, modern C compilers do catch some semantic errors. These are typically reported in the form of warnings, indicating that you might have intended to do this, but you probably didn’t. In order to minimise the number of syntactic and semantic errors you make when starting out writing C code, I recommend turning on all the warnings and errors that your compiler can give (if you’re not sure how, read the manual!). Warnings and errors are there to help you write better code, read them!
Having compared natural and computer languages in the above paragraphs, it is important to realise that the two are very different from one another — mostly, due to increased strictness of programming languages. In approaching programming languages, just as with digital systems in general, you must start a blank slate of understanding. For instance, unlike natural languages, words and sentences in most programming languages should not be interpreted intuitively. Each building block has a very specific technical meaning, separate from that of any everyday words with the same spelling. The connection to the everyday word is only suggestive, and programs usually do not do what the words may intuitively suggest (if these intuitive understanding are sufficiently unambiguous to suggest anything in the first place).
As each building block has a well-defined effect, every single line of code in a program matters, as each has a real impact on the way the final program will run. If you don’t understand every single detail in the code, there’s a good chance you don’t understand the program as a whole. New programmers cannot simply gloss over words in a sentence as you might in English and hope for a sufficient understanding of what a program does. In this series, we will step through the meanings of the various fundamental C99 constructs in turn, considering the impacts and applications of these semantics. If you fail to understand even a single line of code where it is not explicitly indicated as “alien” (or explained later in that chapter), it may be worth revisiting earlier chapters or performing some independent research around the topic.
Alongside strict semantics, programming languages — as we have discussed — have far stricter syntax than natural languages. Missing a single punctuation mark where it should be present can result in an error, as can placing one where it does not belong! This can be frustrating at times, and once again echoes the unforgiving nature of strict digital systems — the compiler cannot be expected to accurately figure out the intentions behind your malformed code. In any case, the compiler errors that result from basic syntactic mistakes can often make these errors fairly trivial to resolve. In general, it’s important to remember that humans did not evolve to craft correct, complex programs, and as such you will make mistakes.
While we’re on the topic of syntax, the construction of the C language may seem rather strange to you at first — like an esoteric artefact from programmers of the past. This is somewhat accurate, but is also true of most languages. Are the rules that make up the C language really any more esoteric than those that define English? In a sense, the syntax doesn’t matter anyway. The mapping from syntax to semantics is totally arbitrary, and different languages have different ways of expressing things. A Lisp program to perform the same task as our “yards to metres” C presented earlier might look something like the following:
(define display-all (lambda args (map display args)))
(display "Enter a number of yards: ")
(define yards (read))
(let ((metres (* yards 0.9144)))
(display-all yards " yards is " metres " metres")
(newline))(define display-all (lambda args (map display args)))
(display "Enter a number of yards: ")
(define yards (read))
(let ((metres (* yards 0.9144)))
(display-all yards " yards is " metres " metres")
(newline))
The contrast between this Lisp code and its C counterpart is immense, and yet many of the same ideas are expressed. Beyond its influence on programmer behaviour and what it makes possible, the syntax of a language is not terribly important. Often, having learned one programming language, a programmer can pick up the syntax of another within an afternoon. The more difficult part is coming to terms with the semantics of the language, and how this “worldview” of sorts influences the way that programs behave and should be written. From another perspective, however, the syntax is ultimately all that matters. The source code of a program can only consist of syntax. The semantics arise on a higher level, from syntactic constructs.
This tension between syntax and semantics exists in all formal systems. For instance, there is a tension between the symbolic structure in formal systems of number theory (such as the series of characters “5 + 2”) and the meta-mathematics that examines properties of this system and attempts to “understand” them on some higher level. The intuitive concept of addition is one way to understand the way that the symbols “5 + 2” can be transformed into the rather different looking symbol “7” through the strict symbolic rules of mathematics. As humans, we are typically more interested in this level of thinking — in semantics (and meta-semantics) rather than pure syntax — however these properties exist only through syntax. Just as an ant colony can have greater ‘desires’ than those of each single ant, the semantics and meaning of a program can be far more than the mere syntax of each single clause. But, alas, all that really exists is the individual ants.
Like any language, familiarity with both the syntax and semantics is exercised through both reading and writing, producing and consuming. Good programmers, like skilled speakers of natural languages, need to be able to perform both of these tasks competently on both the syntactic and semantic levels. Particularly, we have touched on what can constitute reading and writing C code badly, which is very easy to do — especially for beginners. Having established what not to do, and some fundamentals of how computers and programming languages operate, in the proceeding chapters of this series we will step through a number of topics in turn, slowly building up a better idea of the syntax and semantics of the C language. Where relevant, this will also include what things means on the lower level of the physical machine, or what more general concepts may arise on higher levels. As a starting point, the next chapter will involve diving into the nitty gritty details of how we might construct a simple program to output some text to the screen from scratch. This is no small undertaking, but is an extremely valuable first step in understanding C, and ultimately using it to construct useful, correct programs.